最近、正規表現で先頭や末尾には ^ や $ より \A や \z を使った方がいいという話を聞いたり、いろいろな言語を触ったりして少し混乱してきたので、言語ごとの正規表現の違いについてまとめようと思います。
正規表現で入力値の書式のバリデーションをかけることは多くあると思います。例えば 000-0000 といった郵便番号を入力するフォームがある場合は \d{3}-\d{4} などと書きます。もちろんこの書き方ですと郵便番号が 含まれる というパターンになるので、 「〒000-0000東京都」 のような文字列でもマッチしたことになってしまいます。ですのでバリデーション用の正規表現には ^\d{3}-\d{4}$ のような形で常に ^ (キャレット、ハット)や $ (ドル)をつけるのが一般的です。
とりあえずおまじないとして付けているという方も多いと思いますが、やはり何なのかは理解しておいた方がトラブルを回避できると思います。また ^$ 以外にも \A\z\Z という似た動きをする物も存在します。
言語ごとのサポート状況
| 特殊文字 | PHP | JavaScript | Python | Ruby | Java |
|---|---|---|---|---|---|
| ^ | ○ | ○ | ○ | ○ | ○ |
| $ | ○ | ○ | ○ | ○ | ○ |
| \A | ○ | ― | ○ | ○ | ○ |
| \z | ○ | ― | ※ | ○ | ○ |
| \Z | ○ | ― | ※ | ○ | ○ |
○: サポートあり
―: サポートなし
※: Python は \Z のみ存在しますが、動きは他の言語で言う \z です。
挙動
先に実際の動きとして、各特殊文字のマッチする位置を記載します。__\n__\n という文字があった場合、マッチする位置を | で示します。\n は改行に置き換わるものとします。
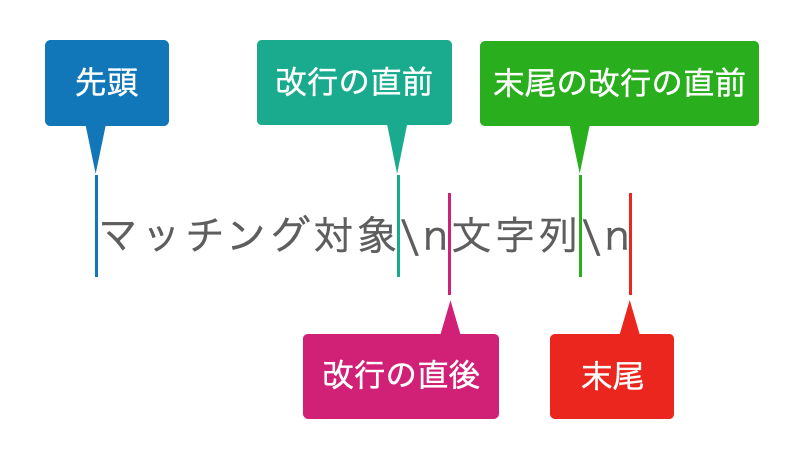
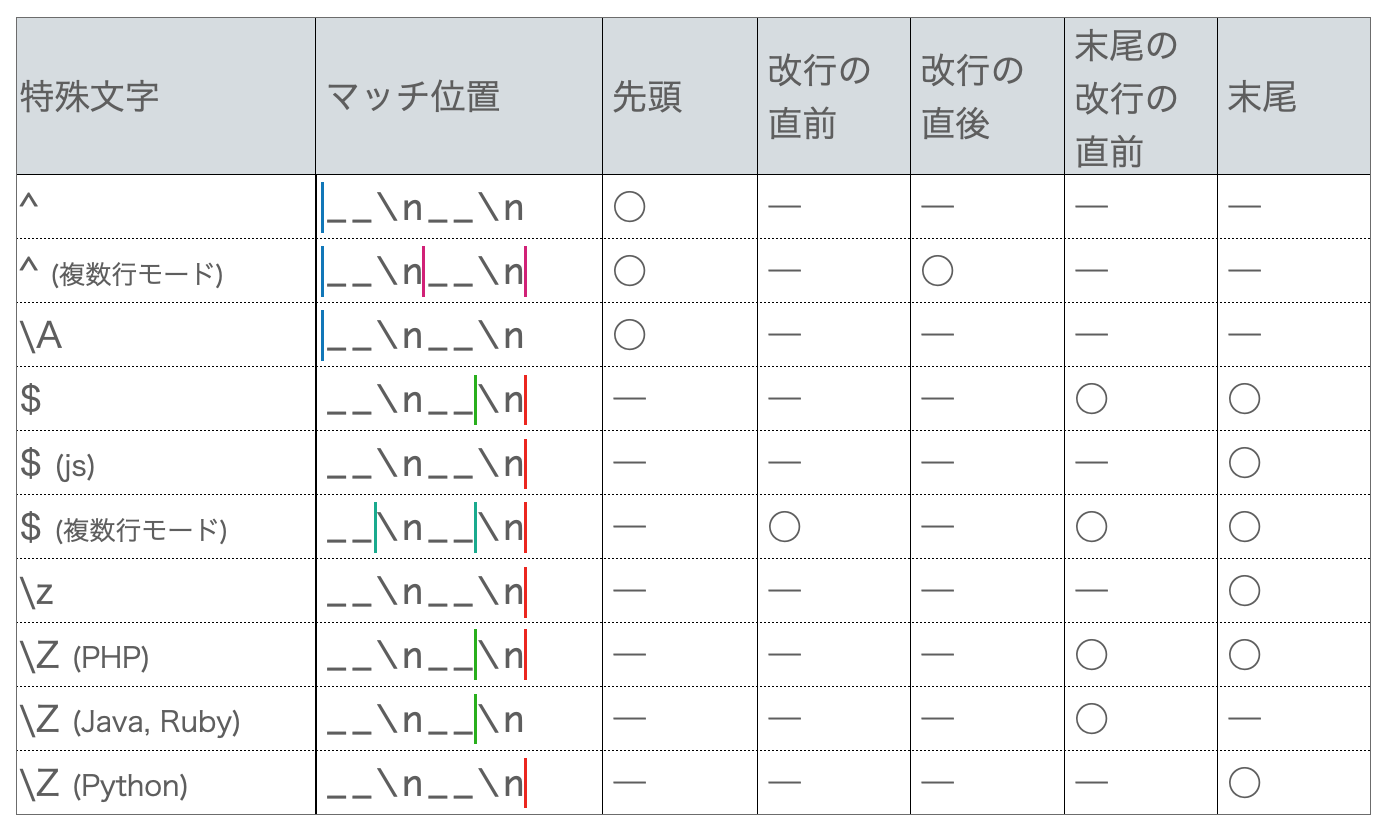
○: マッチする
―: マッチしない
特殊文字
^$\A\z\Z は特殊文字と呼ばれることが多いと思いますが、メタ文字、エスケープシーケンスと呼ばれる場合もあります。ここでは特殊文字で統一します。
今回調査した特殊文字は一般的に以下の意味を持ちます。但し、上記表のように言語ごとに挙動が異なります。
^ : 文字列の先頭にマッチ。複数行モードの場合は各改行の直後にもマッチ。
$ : 終端の直前または終端の改行の直前にマッチ。複数行モードの場合は各改行の直前にもマッチ。
\A : 複数行モードによらず、文字列の先頭にマッチ。
\z : 複数行モードによらず、文字列の末尾にマッチ。
\Z : 複数行モードによらず、文字列の末尾または末尾の改行の直前にマッチ。
複数行モード
000-0000 のような単一行でのデータを扱う場合もあれば、以下のような複数行でデータを表現する場合も存在します。たとえばテキストファイルや HTML の textarea などで、1行1レコードのデータを持たせる場合です。
000-0000
000-0000
000-0000このような場合、各行それぞれに正規表現をマッチさせたいという気持ちになると思います。複数行モードを使用するとそれが可能になります。
PHP や js の場合は '/^\d{3}-\d{4}$/m' のような形で後ろに m を付けると複数行モードになります。その他言語は正規表現をコンパイルするメソッドやクラスのオプション引数にフラグとして渡します。
'/^\d{3}-\d{4}$/m' // PHP
/^\d{3}-\d{4}$/m // JavaScript
re.compile('^\d{3}-\d{4}$', re.MULTILINE) # Python
Pattern.compile("^\\d{3}-\\d{4}$", Pattern.MULTILINE); // Javaここで注意が必要なのは、Ruby は常に複数行モードであるという点です。正確には複数行モードという概念がなく、常に他の言語で言う複数行モードの挙動であるということです。multiline という名前のフラグは存在しますが、これは . の挙動を変えるものなので別物です。
. の挙動
本筋から外れますが . (ドット)について補足します。基本的に . はどの言語でも改行(\n)にはマッチしませんが、フラグを指定すると改行にマッチするようになります。
'/.+/s' // PHP
/.+/s // JavaScript
re.compile('.+', re.DOTALL) # Python
Pattern.compile(".+", Pattern.DOTALL); // Java
/.+/m # Rubyオプション指定できない場合は . の代わりに [\s\S] を使ったりします。空白文字と空白文字以外のどちらかなので、結果全文字ってことになります。
$
$ 記号には不思議な挙動があり、複数行モードでなくても文末が改行の場合はその手前にもマッチします。 PHP と Python と Java はこの挙動をします。具体的には /a$\n/というパターンは a\nにマッチします。
PHP のみこの挙動を変更するオプションが存在します。
'/^a$/D' // PHPまとめ
もっと単純にまとまるかと思いきや、言語ごとにばらばらという結果になりました。完全に文字列の開始と終了にマッチさせたい場合、 js は ^$、PHP、Ruby、Java は \A\z、Python は \A\Zを使用する、といった形で使い分けるのがよさそうです。
ただ、 Python には fullmatch メソッドが、 Java には Matcher クラスの matches メソッドがあるので、バリデーション目的ならば特殊文字ではなくそちらを利用するのも手です。
^ や $ を多用しているのになぜ世の中のシステムは正常に動いているかというと、基本的に入力値には trim 関数(文字列の前後の空白や改行を除去する)を通していたり、最初の郵便番号の例でいうと正規表現とは別に8桁の長さチェックを入れたり、また複数行モードがオフになっているからだったりします。実は正規表現と正規表現以外の要素が絡みあって動作しているので、各要素の理解が必要です。
別システムさわるときや、使用言語が変わるときは、こういった細かい挙動をしっかり調べなければと改めて感じました。
各言語のドキュメント
PHP
https://www.php.net/manual/ja/regexp.reference.escape.php
JavaScript
https://developer.mozilla.org/ja/docs/Web/JavaScript/Guide/Regular_Expressions
Python
https://docs.python.org/ja/3/library/re.html
Ruby
https://docs.ruby-lang.org/ja/latest/doc/spec=2fregexp.html
Java
https://docs.oracle.com/en/java/javase/14/docs/api/java.base/java/util/regex/Pattern.html