
最近の日本企業ではどのような開発手法が使われているのかな、 というのを軽く調べようと思ったのですが、 IPA のソフトウェア開発分析データ集 (ソフトウェア開発データ白書) は残念ながら事業終了1となったようなので、 わかりやすくて正確なグラフをパッと見つけることができませんでした。 ただ、分析レポートがないだけで調査は継続されており、データも公開されていたので、 そのデータを Claude に渡して分析レポートを出してもらいました。
分析結果を載せていますが、この記事の主題はどちらかというと「生成 AI 活用事例」になります。
Claude の分析結果
まずは結果をのせます。
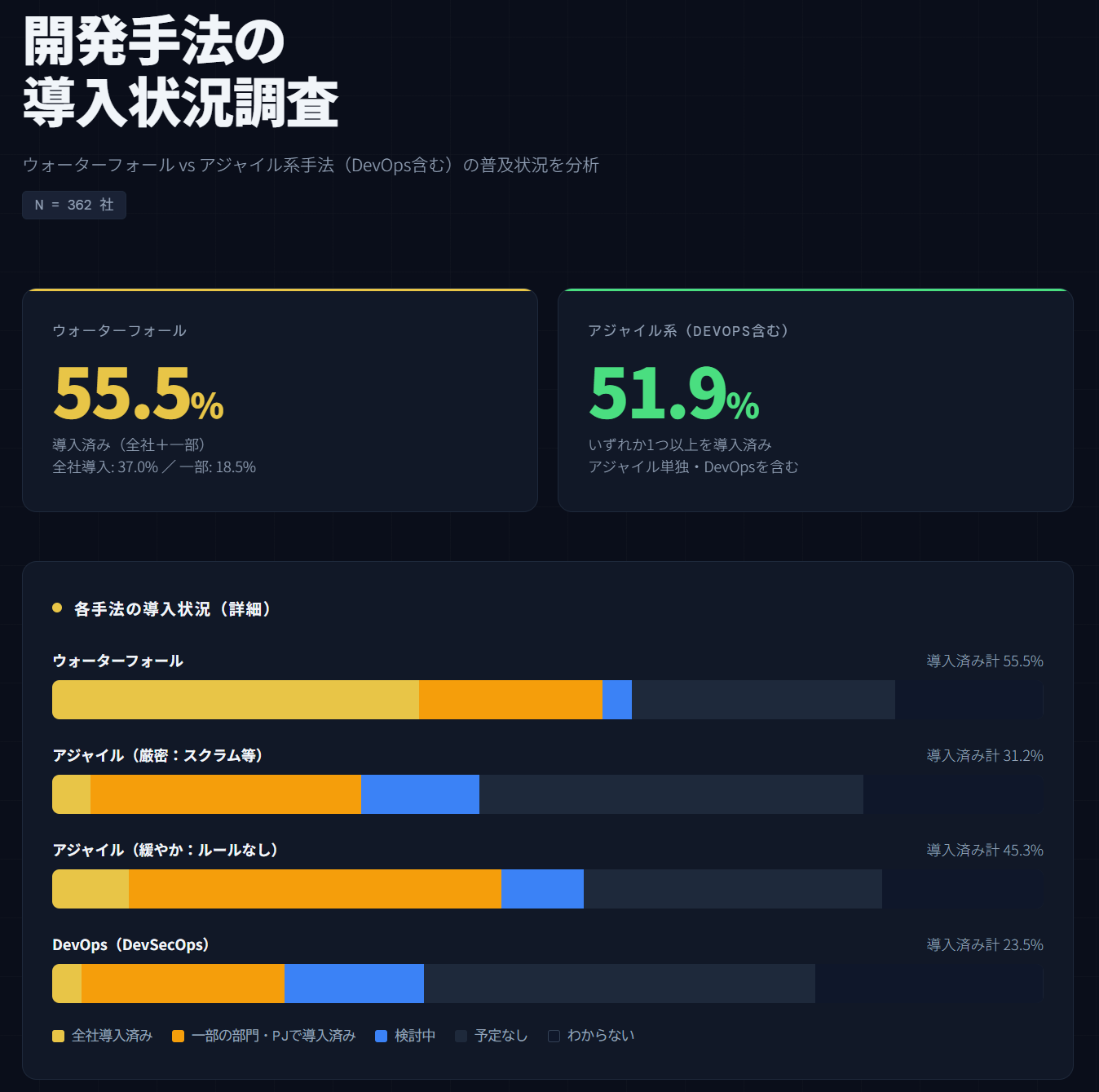
データは IPA の「2025年度ソフトウェア動向調査」 を使用しました。
レポート全文へのリンクは記事後半に載せています。
アジャイルと DevOps は言葉の定義的には違うのですが、 今回見たかったのは現代的な開発手法を導入しているかなので、 DevOps はアジャイルに含めて計上してもらっています。
分析結果としては、まだまだウォーターフォールが強いが、 アジャイルも浸透しているように見えます。2
やったこと
- データの前処理
- Claude 3 に CSV を渡す
- Claude に分析を依頼
データの前処理
IPA の 2025年度ソフトウェア動向調査から CSV をダウンロードしました。
https://www.ipa.go.jp/digital/software-survey/software-engineering/software2025.html
設問数が結構多いので、コンテキストウィンドウ節約のため不要な回答を削除します。 今回は以下の列だけを抽出した CSV を Claude に渡しました。
- Q1-4.企業種別
- Q11-1.開発手法の導入状況(1.ウォーターフォール)
- Q11-1.開発手法の導入状況(2.アジャイル(スクラム等の厳密なルールがある))
- Q11-1.開発手法の導入状況(3.アジャイル(厳密なルールがない))
- Q11-1.開発手法の導入状況(4.DevOps(DevSecOps))
Claude がやったこと
次は CSV を Claude に渡して集計してもらいます。 プロンプトは大したことを書いていなくて、 CSV を添付して以下のように指示4しました。
ウォーターフォール開発とアジャイル開発(DevOps 含む) の割合を調べたいです。 日本でどれくらいアジャイル開発が普及したかを出したいです。
これを受けて Claude は以下の shell というか Python を実行したようです。
cd /home/claude && cat << 'EOF' > analyze.py
import csv
from collections import defaultdict
rows = []
with open('/mnt/user-data/uploads/無題.csv', encoding='utf-8') as f:
reader = csv.DictReader(f)
for row in reader:
rows.append(row)
print(f"総回答数: {len(rows)}")
# カラム名
wf_col = 'Q11-1.開発手法の導入状況(1.ウォーターフォール)'
ag_strict_col = 'Q11-1.開発手法の導入状況(2.アジャイル(スクラム等の厳密なルールがある))'
ag_loose_col = 'Q11-1.開発手法の導入状況(3.アジャイル(厳密なルールがない))'
devops_col = 'Q11-1.開発手法の導入状況(4.DevOps(DevSecOps))'
# 導入済みとみなす回答
ADOPTED = ['1.全社レベルで導入済み', '2.一部の部門・プロジェクトで導入済み']
def count_status(rows, col):
counts = defaultdict(int)
for row in rows:
val = row[col]
# 番号を除いたラベルで集計
if val.startswith('1.'): counts['全社導入済み'] += 1
elif val.startswith('2.'): counts['一部導入済み'] += 1
elif val.startswith('3.'): counts['検討中'] += 1
elif val.startswith('4.'): counts['予定なし'] += 1
elif val.startswith('5.'): counts['わからない'] += 1
return counts
n = len(rows)
wf = count_status(rows, wf_col)
ag_s = count_status(rows, ag_strict_col)
ag_l = count_status(rows, ag_loose_col)
dv = count_status(rows, devops_col)
print("\n=== ウォーターフォール ===")
for k,v in wf.items(): print(f" {k}: {v} ({v/n*100:.1f}%)")
print("\n=== アジャイル(厳密) ===")
for k,v in ag_s.items(): print(f" {k}: {v} ({v/n*100:.1f}%)")
print("\n=== アジャイル(緩やか) ===")
for k,v in ag_l.items(): print(f" {k}: {v} ({v/n*100:.1f}%)")
print("\n=== DevOps ===")
for k,v in dv.items(): print(f" {k}: {v} ({v/n*100:.1f}%)")
# アジャイル系(どれか1つでも導入済み)の人数
agile_adopted = 0
for row in rows:
ag_s_val = row[ag_strict_col]
ag_l_val = row[ag_loose_col]
dv_val = row[devops_col]
if any(v in ADOPTED for v in [ag_s_val, ag_l_val, dv_val]):
agile_adopted += 1
wf_adopted = sum(1 for row in rows if row[wf_col] in ADOPTED)
print(f"\n=== 導入済み集計 ===")
print(f"ウォーターフォール導入済み: {wf_adopted} ({wf_adopted/n*100:.1f}%)")
print(f"アジャイル系いずれか導入済み: {agile_adopted} ({agile_adopted/n*100:.1f}%)")
EOF
python3 analyze.py出力
総回答数: 362
=== ウォーターフォール ===
全社導入済み: 134 (37.0%)
一部導入済み: 67 (18.5%)
予定なし: 96 (26.5%)
わからない: 54 (14.9%)
検討中: 11 (3.0%)
=== アジャイル(厳密) ===
予定なし: 140 (38.7%)
一部導入済み: 99 (27.3%)
検討中: 43 (11.9%)
わからない: 66 (18.2%)
全社導入済み: 14 (3.9%)
=== アジャイル(緩やか) ===
一部導入済み: 136 (37.6%)
予定なし: 109 (30.1%)
全社導入済み: 28 (7.7%)
わからない: 59 (16.3%)
検討中: 30 (8.3%)
=== DevOps ===
予定なし: 143 (39.5%)
一部導入済み: 74 (20.4%)
わからない: 83 (22.9%)
検討中: 51 (14.1%)
全社導入済み: 11 (3.0%)
=== 導入済み集計 ===
ウォーターフォール導入済み: 201 (55.5%)
アジャイル系いずれか導入済み: 188 (51.9%)レポート全文
上記結果に追加で以下の指示を出したレポートを乗せておきます。
- 企業種別ごとの結果も出力して
- 出典を明記して
- noindex 付けて
- Claude が生成したことを補足して
- ブログへのリンクを追加して
まとめ
数字だけ出してもらえればよかったのですが、 結構きれいな分析レポートとグラフを出してくれたので驚きました。 あまり正確性は求められない5が分かりやすいデータをさくっと出したい時は重宝しそうです。
Footnotes
-
↩2020年から書籍版「ソフトウェア開発データ白書」の名称を「ソフトウェア開発分析データ集」に変更
...
事業終了に伴い「ソフトウェア開発分析データ集」の今後の発行予定はございません。
https://www.ipa.go.jp/digital/software-survey/metrics/index.html -
「ソフトウェア開発データ白書 2018-2019」では9割、 というかほぼ10割ウォーターフォールというグラフが載っていたので、集計方法の違いが気になる ↩
-
今回使ったのは Claude Desktop。モデルは Sonnet 4.6。 ↩
-
目的を語っているだけなので、指示というか圧 ↩
-
本当は集計結果の検証をしなければいけないのですが、今回は断念しました。 生成 AI は求めたもの以上の成果を出してくるのでレビューの負荷が高くなってしまう傾向があります・・・ ↩